通过简单方法实践学习 RAG—如何构建真正理解你的
如何打造真正理解业务的AI

这篇文章讲什么?
本文将带你从零开始构建一个完整的 RAG(检索增强生成,Retrieval-Augmented Generation)系统。我们以一个虚构的公司为例,该公司需要让员工能够即时访问庞大的知识库。你将看到实际的代码、架构决策,以及一步步将分散的文档转化为智能问答系统的实现过程。
技术栈(Tech Stack)

让我们来设计
我构建这个系统时设计了四个独立层级,目的是实现清晰的职责分离(Separation of Concerns)。每个层级都有明确的职责,这种设计让代码更易于维护和扩展。
用户界面层(顶层)
这里我设置了三个入口点 —— CLI 运行器(CLI runner)、演示运行器(demo runner)和 API 接口。这样设计是因为用户需要通过不同方式与系统交互:
1. CLI 提供带颜色标识的即时反馈
2. 演示程序直观展示系统能力
3. API 支持与其他应用集成
核心应用层(中上层)
我将核心RAG引擎(Core RAG Engine)放在这里作为中央协调器。这个组件负责主要逻辑——接收查询、协调检索并生成响应。我将文档处理器(Document Processor)和配置组件(Configuration)与它并列放置,因为它们直接支撑核心功能。文档处理器负责为存储准备内容,而配置组件则管理所有设置。
服务集成层(中下层)
在这里,我创建了两个关键接口——LLM客户端(LLM Client)和向量存储(Vector Store)。将它们分离是因为它们处理不同的外部服务:LLM客户端负责管理所有与OpenAI的交互(如嵌入和聊天功能),而向量存储则处理ChromaDB的操作。这种分离设计使得我可以独立替换其中任一服务,而不会影响另一个。
数据存储层(底层)
我将实际的外部服务放在这一层 —— OpenAI API 和 ChromaDB。它们是整个系统的基础架构,其他所有组件都建立在其之上。

数据流设计(Data Flow Design)
我选择用曲线箭头而非直线来展示数据在系统中的自然流动路径。一个典型的查询(query)会这样流转:
我将箭头设计为从核心RAG引擎(Core RAG Engine)向外分叉延伸,因为这个组件需要同时与多个服务进行交互。在处理查询时,它既需要向量搜索能力,也需要访问语言模型。
我为什么选择这个架构
我采用这种结构是为了实现模块化(modularity)。每个组件只负责单一功能,这样不仅便于测试,还能在不影响整体系统的情况下单独替换某个模块。例如,只需更换LLM Client组件,就能轻松从OpenAI切换到其他大语言模型(LLM)服务提供商。
我还特别考虑了系统的可扩展性。核心RAG引擎(Core RAG Engine)并不关心存储或语言模型的具体实现细节,它只通过接口进行交互。这意味着我可以轻松添加新的文档类型、更换不同的向量数据库(vector databases)或改用其他LLM服务商,而完全不需要修改核心逻辑。
通过色彩进行视觉分组,能帮助开发者直观理解哪些组件需要协同工作,哪些可以独立修改。这种架构设计将复杂的RAG(检索增强生成)系统转化为多个相互关联的模块,使它们既能各自管理又能无缝协作。
cli_runner.py
主函数设置:我创建了这个主函数,用于初始化 colorama 库(实现彩色终端输出)并加载配置。我希望为用户提供一个视觉上更吸引人的命令行界面。

集合清理逻辑:我编写了这段检查代码,用于判断文档是否已存在于集合(collection)中。如果存在,就先清空它们。这样做的目的是为了让CLI每次运行时都能从头开始,避免产生重复文档。
文档加载:我在这里向RAG(检索增强生成)系统添加示例文档。我将此步骤放在清空操作之后,因为用户启动CLI时,需要立即有数据可供查询。
交互式查询循环:我创建了这个 while 循环,它会持续接收用户提问,直到用户输入"quit"。我希望让界面保持对话式的交互体验,并实现持久化会话,这样用户就能在一次会话中连续提出多个问题。
错误处理与结果展示:我将查询执行过程封装在 try-catch 代码块中,并使用彩色格式输出结果。这样做的目的是让错误提示更优雅,同时通过颜色区分使结果更直观——既能显示答案,又能清晰展示信息来源。
config.py
环境变量加载:我使用了 python-dotenv 从 .env 文件加载环境变量。选择这种方式是因为它可以将敏感的 API 密钥(API keys)与源代码分离。

配置字典(Configuration dictionary):我返回一个包含所有必要配置值的字典,并为可选设置提供默认值。这样设计是为了将所有配置集中在一处,便于修改设置。
core_rag.py
CoreRAG 类初始化:我创建这个类是为了协调整个 RAG(Retrieval-Augmented Generation)流程。在这里实例化 LLM(大语言模型)客户端和向量数据库,因为它们是两个需要协同工作的核心组件。

add_documents 方法:我将文档添加操作委托给向量数据库(vector store)处理,同时传入 LLM 客户端用于生成嵌入向量(embedding)。这样设计是为了让核心 RAG 类专注于协调工作,而不必关心具体实现细节。
search_documents方法:我创建这个方法来查找与查询相关的文档。传入嵌入模型(embedding model)参数,以确保文档和查询的嵌入向量保持一致。
generate_response 方法:我会构建一个包含检索到的上下文和用户问题的提示(prompt)。采用这种格式是因为大型语言模型(large language models)在明确的上下文和清晰的指令下表现最佳。
查询方法(query method):我将搜索和生成整合成一个方法,直接返回结构化响应。这样设计是为了提供一个简洁的接口,通过单次调用就能处理整个RAG(检索增强生成)流程。
demo_runner.py
demo_basic_usage 函数:我创建这个函数是为了展示 RAG(检索增强生成)系统如何使用预定义问题工作。其中包含了文档加载和多个测试查询,以演示完整的工作流程。

demo_document_processing 函数:我编写这个函数是为了展示如何处理网页和文件。由于网络访问可能不稳定,我还加入了网页抓取时的错误处理机制。
交互式演示函数(interactive_demo):我构建了这个功能,让用户可以通过提问进行更直观的体验。在会话过程中,用户可以使用"info"命令随时查看当前集合状态。
主演示选择器(Main demo selector):我设计了一个菜单系统,让用户可以自由选择要运行的演示案例。采用这种结构是为了让各个演示模块化且易于访问。
doc_processing.py
DocProcessor类(Document Processor):我创建这个类来处理所有文档处理任务,包括文本文件、网页和原始文本。将这些功能集中在一起,是因为它们都涉及相似的分块(chunking)和元数据(metadata)操作。

文本分割:我使用了LangChain的递归字符文本分割器(
RecursiveCharacterTextSplitter)将文档拆分为可管理的片段。选择这种方法是因为与简单的字符分割相比,它能更好地保持上下文关系。
网页处理:我编写了`load_web_page`方法来获取并清理HTML内容。由于只需要用于RAG(检索增强生成)的实际文本内容,我移除了脚本(script)和样式(style)标签,并清除了空白字符。
分块处理与元数据:我创建了包含文本、元数据(metadata)和唯一ID的文档对象。采用这种结构是因为向量数据库(vector store)需要这种特定格式才能正确建立索引和实现检索。
示例文档功能:我添加这个功能是为了提供即时的测试数据。我编写了三个不同主题的文档,用来演示系统如何处理多样化的内容类型。
llm_client.py
LLMClient类:我创建了这个封装OpenAI客户端的包装器,目的是抽象化API调用。这样做是为了将来如果需要更换不同的语言模型(Language Model),能够更加方便。

create_embedding方法:我通过指定正确的模型来处理向量嵌入(embedding)的创建。之所以这样设计响应提取结构,是因为OpenAI返回的向量嵌入采用了特定的嵌套格式。
聊天方法:我通过系统消息和用户提示设置了聊天补全功能。参数中包含了温度值(temperature)和最大令牌数(max_tokens),用于控制回答的多样性和长度。
vector_store.py
VectorStore类:我创建这个类是为了封装所有ChromaDB操作。我在构造函数中处理集合(collection)的创建和获取,因为必须先存在集合才能进行任何操作。

add_documents 方法:我能够一次性处理多个文档,生成嵌入向量(embeddings)并存储附带元数据。我采用批量操作的方式,因为这比逐个处理文档效率更高。
搜索方法:我先生成一个查询向量(query embedding),然后搜索相似的文档。最后将结果格式化为统一的结构,因为系统其他部分需要特定的字段名称。
集合管理(Collection management):我添加了获取集合信息和清空集合的方法。这些实用工具很有必要,因为开发过程中用户经常需要检查状态或重新开始。
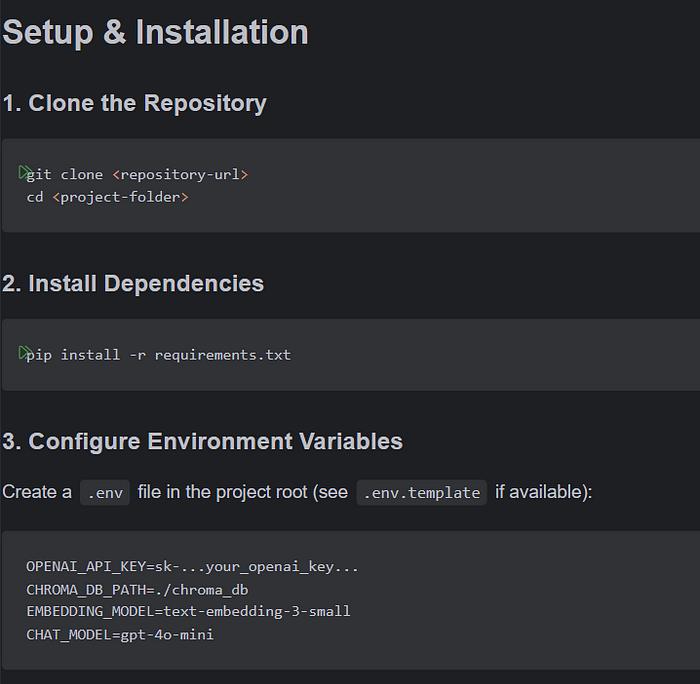
让我们开始配置
边做边学RAG:通过简单方法实践/README.md 位于主分支 ·…
github.com
让我们开始吧



最后总结
未来商业AI(Artificial Intelligence)的发展方向,是能够无缝融入现有工作流程,同时提供智能洞察的系统。RAG(Retrieval-Augmented Generation)技术仅仅是这场变革的开端。很快,我们将看到这样的AI助手:它们不仅能回答问题,还能主动提供解决方案、预测需求,并自动化复杂的决策流程。


