从 “虚拟女友” 到互动游戏:AI 角色扮演如何玩出 “真实感”?
文丨jamarcus腾讯互动娱乐实习研究员
夏洛克不是侦探腾讯互动娱乐研究员
AI角色扮演以“超写实对话”与“交互式叙事”两大功能逐渐成为当下游戏创作中的重要课题。如果你对AI游戏创作有着独特的创意与灵感,鹅博士邀请你一起参与2025腾讯游戏创作大赛-AI创作赛道,35万奖金池+业内导师助你实现创意落地,点击链接了解更多资讯。AI创作者集结!2025腾讯游戏创作大赛-AI创作赛道等你来挑战
前言:从“虚拟女友”到互动游戏
最近网上吵得火热的Grok“虚拟女友”,简直把“线上搭子”的体验玩出了新花样——能顺着你的梗接话,会在你吐槽老板时帮你“骂两句”,甚至连撒娇时的语气词都带着恰到好处的“真实感”。
这种让人忍不住想多聊两句的互动,正是AI角色扮演的魅力所在。通过精细化的角色设定与交互设计,我们可以祛除传统智能助手的浓厚“工具感”,赋予AI深度社交和情感陪伴的能力。
这种能力,具体落地为角色扮演的两大核心应用场景:追求极致对话质感的“超拟人方向”与构建沉浸式叙事的“交互游戏方向”。它们从虚拟陪伴到互动娱乐,复刻着真实人际连接的温度。
一、角色扮演的背景与应用场景
我们基于最近的实践,进一步地对角色扮演的应用进行了划分并总结为以下两个主要应用方向:

方向一:超写实对话与情感陪伴
此方向是当前市场的主流,它将LLM定位为一个无限接近真人的对话伙伴,追求极致的对话自然度和情感连接。
定义与代表产品:
这类产品的目标是复刻真实人类的聊天风格,回复通常更短、更口语化,并带有丰富的语气和情绪色彩。
应用形态包括:Grok4、纯角色聊天App(如星野、猫箱)、虚拟主播、情感陪伴机器人等。
核心困境:
智商与“人味”的内在冲突——这是超写实方向最根本的矛盾。一个“聪明”的LLM被训练去认知并输出事实性知识(如“1+1=2”),而一个“真实”的人类在面对同样问题时,可能会基于情感、态度或情境给出千变万化的非标准答案(如“你觉得我像不知道吗?”“你猜?”)。将包含大量事实性知识的LLM“改造”成一个超写实的人类对话者,本身就存在巨大的技术张力。
关键技术挑战与研究路径:
挑战一:Persona污染与知识冲突
在训练中,模型极易将角色数据中的特定风格或口头禅错误地泛化为“事实性知识”。这种污染会严重“拉低”模型在通用能力上的表现,即所谓的“智力退化”。
- 探索路径:隔离策略:通过在提示中设置显式的模式区分符(如[RolePlayMode]),是一种基础的隔离方法,但实践证明其效果有限,污染仍会发生。
- 数据与算法对齐:更有效的方法是在数据和算法层面进行处理。例如,使用DPO或成对的SFT数据,明确告诉模型在A场景下某种回答是合适的,但在B场景下是不合适的。

Neeko的整体框架
模块化方法:Neeko等研究中使用的参数高效微调(PEFT),特别是为每个角色训练独立的LoRA适配器,也可以在物理层面隔离不同角色的参数,是解决角色间污染的有效技术手段。
挑战二:“真实感”语料的获取与应用困境
超写实的对话风格极度依赖真实的、高质量的语料,其“语感”和“品味”很难通过纯合成数据复现。但直接使用现实世界的数据(如公开社交语料LCCC、个人聊天记录)面临巨大困难。
- 人设缺失:LCCC这类数据缺乏发言人信息,无法构建角色档案,直接训练会导致严重的“人设幻觉”。
- 隐私与成本:个人聊天记录虽有人设,但涉及隐私,且为海量对话手工编写角色卡成本过高,少量使用又会导致过拟合。

LiveChat的整体结构
- 探索路径:当前的研究正致力于半自动化地构建高质量、带人设的语料库。LiveChat等工作,通过从直播、社交平台等场景中,结合用户公开的个人信息,来构建大规模的、隐式包含Persona的对话数据集,是解决这一困境的重要方向。
挑战三:长程对话一致性vs.长文档理解
角色扮演所需的长上下文能力,与传统的大海捞针式文档问答有着本质区别。后者考验的是信息检索能力,而前者考验的是在数百轮连续对话中,维持人格、情感和记忆高度一致的能力,难度呈指数级增长。目前,几乎不存在公开的、由真实对话构成的超长轮次(如100ktokens)训练数据。
- 探索路径:这再次指向了架构革新的必要性。GenerativeAgents等研究中提出的长期记忆机制,是解决这一问题的根本路径。如何让模型在第100轮对话时,依然清晰地记得第1轮对话中建立的情感连接和关键信息,并对最初的SystemPrompt保持高度关注,是所有情感陪伴类产品必须攻克的难关。

GenerativeAgents
方向二:交互式叙事与世界模拟
此方向将LLM定位为一个动态世界的核心引擎,用户不再是简单的对话者,而是成为一个复杂、可变世界中的“玩家”。

定义与代表产品:
这类产品的典型代表是Character.AI、TavernAI(及各类“酒馆”模型)。它们的核心体验更接近于一个开放世界的文字角色扮演游戏(Text-basedRPG)或动态剧本杀。模型输出的通常是较长的文本段落,其中不仅包含角色的对话,还混杂了大量的情节推进、环境描写、内心独白以及角色状态的描述。
核心特征与能力解构:
这类模型的响应可以被解构为三个关键组件,共同构成一个完整的“世界回合”:
- 行动(Action):基于用户输入和当前情境,角色所做出的决策与行动。
- 舞台(Stage):因角色的行动而引发的世界状态或角色关系的变化。这可能包括情节的推进、新NPC的出现,或是角色好感度、生命值等数值的变动。
- 叙述(Query/Narration):角色最终说出的话语,以及对整个场景的旁白描述。
关键技术挑战与研究路径:
- 对“Action”的要求:强大的逻辑推理与规划能力。角色的行动决策必须符合其性格、身份和当前处境,这要求模型具备极强的SystemPrompt遵循能力和逻辑推理能力。相关研究,如AgenticAI的探索(以GenerativeAgents为代表),正是为了让模型能够进行合理的长期规划和行动决策。

- 对“Stage”的要求:高度的世界一致性与格式遵循。世界状态的变更要求模型具备强大的长上下文一致性,确保世界规则不被破坏。同时,更新好感度等数值则对模型的格式遵循甚至数学能力提出了要求。RPGBENCH等基准,正是通过将LLM置于游戏或虚拟世界环境中,来评估其维持世界一致性的综合能力。

- 对“Query/Narration”的要求:卓越的叙事与文学创作能力。此方向对模型“写小说”的能力要求极高。如BookWorld等项目探索的,从文学作品中学习并生成互动故事的能力,是这一方向的核心竞争力。
一个核心悖论:有趣的是,要实现一个好的“交互游戏”模型,其所需的能力(强大的推理、逻辑一致性、遵循复杂指令)反而与一个顶级的“通用助手”模型高度重合。这解释了为何此方向需要更大、更“聪明”的基座模型。
二、如何实现角色扮演?
角色扮演作为一种互动体验,其实现手段始终在演进——从早期的人工设计逐步走向技术赋能。
早期的角色扮演,主要依赖预设脚本(如游戏NPC的固定对话)或人工实时操控(如虚拟主播背后的配音团队)。这些方式虽能完成基础的角色互动,却始终受限于两大瓶颈:一是灵活性不足,角色行为难以突破预设框架;二是规模化成本过高,难以覆盖多样化的用户需求。因此,它们始终无法满足用户对“自然、个性化、沉浸式互动”的深层追求。
近年来,随着大语言模型(LLM)的快速发展,通用模型(如ChatGPT)开始被尝试应用于角色扮演场景。尽管这类模型在互动流畅度上取得了一定突破,但本质上仍属于“工具的跨界借用”——其核心设计目标是高效处理信息、完成通用任务,角色扮演对它们而言只是一项“临时任务”。这种定位使其在角色演绎中存在天然缺陷:例如难以维持角色人格的一致性、缺乏情感共鸣的深度、互动模式被动僵化等。
当用户对角色扮演的需求从“功能性对话”转向“情感陪伴”与“叙事共创”时,通用模型的局限性愈发突出。市场迫切需要一种专门优化角色模拟能力的技术手段——它既要突破通用模型的工具属性,又要解决传统人工手段的效率瓶颈,真正成为“角色的载体”而非“角色的执行者”。
正是为了填补这一空白,将角色扮演从“临时互动任务”升级为“极致沉浸式产品”,角色扮演大模型这一专门技术才应运而生。
要理解这类专用模型的核心价值,需先明确两个关键前提——它们既是理解通用模型局限的钥匙,也是把握角色扮演大模型突破点的基础:
1、当前大模型是否具备“自我意识”?
答案是否定的。无论是通用模型还是角色扮演大模型,本质都是通过数据学习人类行为模式的“模拟系统”,所有“角色表现”均源于对语言、情感和逻辑的算法重组,而非独立意识。这意味着,两者的差异不在于“是否有意识”,而在于“模拟的目标是否聚焦于角色本身”.
2、为何通用大模型的回答常带“辨识性”?
这源于其核心设计目标:通用模型通过监督微调、人类反馈强化学习等技术,最终要实现“人类通用偏好对齐”——说白了,就是要成为一个“符合大众期待的智能助手”。这种定位使其输出自带鲜明的“助手风格”:语言正式、书面化,常带说教口吻(如“总之...”“记住...”),甚至会不自觉地纠正用户表述(如“严格来说,这个说法不够准确...”)。这种风格是为了高效解决问题而设计的,却与角色扮演所需的“角色化表达”(如傲娇语气、江湖腔调)天然冲突。
作为提效工具,通用模型的“助手风格”无可厚非;但在角色扮演场景中,这种风格恰恰成了沉浸感的“破坏者”。对于更广泛的非技术用户而言,他们期待的不是“高效的信息处理机”,而是“能撒娇、会吐槽、有温度的角色伙伴”——娱乐性与情感共鸣才是留存核心。此时,通用模型的正式感、说教感会产生强烈违和感,使其始终无法摆脱“客串”的生硬感。
而这,正是角色扮演大模型的核心突破点。以Character.AI为代表的产品之所以快速崛起,本质上是因为它们跳出了“助手定位”的框架:不再追求“通用正确”,而是将“角色一致性”“情感真实感”作为核心训练目标——比如让“傲娇少女”始终用带刺的语气藏住关心,让“江湖侠客”开口就是“兄台”“赐教”。这种对“角色化表达”的定向优化,精准击中了用户对“高度定制、拟人化、有温度交互”的需求。
因此,所谓角色扮演大模型,正是通过重构训练目标与技术路径,专门解决“如何让模型像角色一样思考、表达、互动”的技术方案。
理解角色扮演模型的核心价值,关键在于厘清其与通用大模型(如ChatGPT等)在概念与表现上的根本差异:

正是这种从“工具”到“演员/产品”的转变,使得角色扮演模型在实现图灵测试所追求的“以假乱真”的拟人化交互上迈出了关键一步。它极大地激发了用户的交流欲望和情感投入,满足了人类深层次的情感连接与娱乐需求。
相信上面的背景信息已经比较充足。接下来,让我们逐步拆解角色扮演的完整技术栈与落地路径!
三、角色扮演的实现与优化

Persona的设计与实现
Persona为大语言模型赋予特定身份、人格或角色设定,使其在交互中模拟相应的言行风格。根据近期综述,Persona可划分为三类:
一、角色型Persona
此类Persona旨在让LLM扮演一个具体、独立的个体,拥有明确的身份和完整的人格。其核心是“一对一”的深度模拟,根据其来源可分为两类:已存在角色与合成角色。
对于已存在角色:专注于复现现实世界或虚构作品中已存在且广为人知的人物,例如历史名人(如苏格拉底)、动漫人物(如哆啦A梦)。其核心在于追求极致的保真度,忠实地还原角色是该领域的“最高纲领”——这要求模型不仅模仿表层语言风格,更需深入角色的“心智”,准确掌握其知识体系、性格特质、价值观乃至动态的人际关系网络。具体来看,该领域面临三大核心挑战及对应的前沿对策:
1、知识准确性:对抗“角色幻觉”
- 挑战在于,LLM在扮演角色时,常会捏造不符合其设定的“事实”,或混淆不同角色的知识(即“角色幻觉”);同时,角色知识具有时效性(如《哈利・波特》第三部中的斯内普不应知道最终结局),模型很难准确把握特定时间点的状态。
- 对此,研究界从数据和算法两方面入手:例如,MitigatingHallucinationinFictionalCharacterRole-Play专注于开发专门的数据集和方法来减少虚构角色的幻觉;LargeLanguageModelsMeetHarryPotter则通过构建高质量的双语角色对话数据集,为模型提供更可靠的“养料”。
2、长期一致性:构建稳固的“角色内核”
- 挑战在于,长轮次对话中,角色设定容易出现“漂移”或“崩塌”,难以维持稳定的人格表现。
- 对策以架构层面的创新为主:Character-LLM提出的可训练“角色记忆模块”是该领域的里程碑式工作;后续研究如PsyMem进一步探索了“细粒度心理对齐”和“显式记忆控制”,力图让角色的记忆和心理状态更加可控;CoSER则研究如何“协调”角色扮演的多个方面(如背景知识、对话风格、核心动机),以实现更全面的内部一致性。
3、评估体系:从“能否扮演”到“扮演多像”
- 挑战在于,如何科学、客观地量化角色扮演的“保真度”,避免评估流于主观。
- 前沿对策呈现两大趋势:一是构建综合性基准,RoleLLM开创性地提出了包含多维度能力的评测框架,在此基础上,CharacterBench和CharacterEval等工作提供了规模更大、维度更丰富的中文及跨语言评测基准,成为业界衡量模型角色定制能力的“标尺”;二是创新评估方法,InCharacter独创的“心理访谈”方法,从心理学维度深度评估人格的忠实度,极具启发性;SocialBench则专注于评估角色的“社交能力”,将评测推向更实用的层面。
此外,该领域的新兴前沿值得关注:一是多模态沉浸式交互,OmniCharacter和MMRole的研究正引领角色扮演进入多模态时代,融合声音、图像,旨在实现“无缝的音语人格交互”,打造更具沉浸感的智能体;二是从个体到社会模拟,BookWorld展示了更宏大的愿景,即不再满足于模拟单个角色,而是基于文学作品构建出能够自主交互的“智能体社会”,用于创造性的故事生成。
对于合成角色:指从零开始创造一个全新的、原创的虚拟角色,该角色在现实世界和现有作品中没有原型,其身份、性格、背景故事完全由开发者或用户定义,例如游戏中的原创NPC、品牌的虚拟代言人、个人定制的AI伴侣。其核心目标是创造内部一致、人格可信且富有吸引力的全新角色,重点在于“创造”而非“复刻”。该领域的核心挑战与前沿对策如下:
1、规模化的人格定义与注入
- 挑战在于,如何高效、规模化地将抽象的人格特质(如“傲娇”“治愈系”)转化为具体的模型行为模式?
- 对策方面,大规模合成数据是当前的主流解法。OpenCharacter和ScalingSyntheticDataCreationwith1,000,000,000Personas等研究展示了工业界的实践:通过生成海量的合成Persona数据来训练可定制的角色扮演模型,实现了从“手工作坊”到“工业化生产”的跨越。其底层技术依赖于精心设计的“角色卡”和“宪法式提示”来指导生成过程。
2、可信度与常识推理
- 挑战在于,合成角色容易显得空洞、模板化,缺乏真实世界的常识,导致行为不可信。
- 对策的关键是为角色注入常识知识:Stark的研究专注于构建包含“人格常识知识”的社交化长程对话模型,让角色的行为更符合现实逻辑;此外,一致性增强技术(如记忆模块)同样是确保角色长期可信的基础。
3、无“标准答案”下的评估
- 挑战在于,由于合成角色没有“原作”作为参照,如何评估其扮演质量?
- 对策是设计专门的评估任务和环境:PersonaGym是一个里程碑式的项目,它提供了专门的评估竞技场,用于测试和比较不同Persona智能体在各种任务中的表现;RoleMRC则构建了一个细粒度的复合基准,同时评估角色扮演和指令遵循能力,这对于需要执行任务的合成角色尤为重要。
二、群体型Persona
此类Persona旨在模拟具有共同社会或人口统计学特征的群体,并非模拟任何具体个体,而是通过激活模型在海量数据中学习到的群体关联与认知,来代表一个职业(如专家)、文化背景(如某国人)或性格类型(如外向者)的“典型”形象。
核心目标是快速、低成本地生成符合大众普遍认知的群体风格,这不仅用于娱乐性角色扮演,在特定任务中也极具价值。该领域最突出的核心挑战是不可避免的偏见、刻板印象与漫画化——这是群体Persona与生俱来的“原罪”,也是研究者们最关注的焦点,具体表现与前沿对策如下:
1、偏见的内隐与放大
- 挑战在于,模型的偏见不仅体现在复述公开偏见上:BiasRunsDeep的研究揭示,偏见深植于模型的“内隐推理”过程中,即便没有明确提示,模型也会自发展现出带有偏见的倾向;更危险的是,ToxicityinChatGPT的研究发现,为模型分配某些群体Persona后,其输出的毒性会不降反升,说明Persona设定可能成为放大偏见的“催化剂”。
2、从“反映”到“夸张”:漫画化
- 挑战在于,模型不仅会反映刻板印象,还倾向于将其简化和夸张:CoMPosT的研究精准地将此现象定义为“漫画化”,即模型会抓住群体最突出、最脸谱化的特征进行过度演绎(如“程序员必穿格子衫”),从而扭曲对一个群体的真实认知。
针对上述挑战,前沿研究与对策已从“打补丁”式的修正转向构建更根本、更深入的对齐框架:
- 构建基于价值与信念的对齐框架:这是当前最前沿的思路。VBN-Reasoning提出的“价值-信念-规范”推理框架是一个里程碑,它不再简单命令模型“不要有偏见”,而是让模型理解特定文化群体背后的核心价值观和信念体系,并以此为基础推理行动,做出更符合伦理的决策;BeyondDemographics的工作也提出了类似的“人类信念网络”对齐方法,力图使模型行为与深层的人类社会认知保持一致。
- 深入探索复杂的人文维度:研究者开始聚焦单一但复杂的维度,例如CultureLLM专注于将不同文化背景下的独特价值观、社交礼仪和沟通方式融入LLM,这对于构建真正具备跨文化能力的模型至关重要。
- 对“角色”本身的Z批判性反思:除了修正负面影响,学界也在反思赋予LLM何种角色是“有益”的。Is"AHelpfulAssistant"theBestRoleforLargeLanguageModels?等研究通过系统性评估,探讨了不同社会角色(如合作者、批评家、导师)对用户行为和任务结果的影响,为设计负责任、有益的Persona提供了重要参考。
三、个性化Persona
此类Persona指为每一个独立用户创建和维护一个动态的、独一无二的数字化人格档案,是LLM应用的“圣杯”之一,旨在从“通用智能”走向“专属智能”,最终实现数字孪生的宏伟愿景。
核心目标是让模型深度理解并适应单个用户的沟通风格、知识背景、兴趣偏好和个人经历,提供高度相关且持续演进的响应。该领域的主要挑战与前沿研究、对策如下:
如LaMP这篇综述所总结,个性化面临三大核心且相互交织的挑战:
- 动态学习与灾难性遗忘:模型需在持续交互中学习新信息,但极易忘记用户的长期偏好或早期信息。
- 隐私与数据安全:个性化建立在海量个人数据之上,如何在利用数据的同时确保其不被泄露或滥用,是技术和伦理的双重红线。
- 通用性与个性化的平衡:过度个性化可能损害模型原有的通用知识和推理能力,使其变得“狭隘”。
针对上述挑战,涌现出不少研究与对策:
1、数据基础:构建高质量的个性化语料
- 来源:高质量的个性化数据是基础,LiveChat通过收集大规模直播平台的主播-观众互动数据,为“主播人设”这种特定形式的个性化研究提供了宝贵资源。
- 构建:PersonalityChat等工作探索从对话中提炼用户的“事实”和“特质”,以此构建对话模型;随着技术发展,MPCHAT已将个性化数据扩展至多模态领域,融合文本、图像等信息构建更全面的用户画像。
2、实现方法:从“重量级”训练到“轻量级”引导
- 重量级方法(训练与微调):针对追求深度融合的场景,PersLLM提出“人格化训练”方法,在预训练阶段就注入个性化元素;DEEPER则代表更精细的在线优化思路,通过“定向人格提纯”技术,根据用户新反馈动态、高效地更新模型,直接应对“动态学习”的挑战。
- 轻量级方法(提示与示范):针对需要快速适应的场景,Show,Don'tTell证明,通过少量对话范例(DemonstratedFeedback)进行上下文学习,就能高效引导模型对齐用户风格,大幅降低个性化门槛。
3、评估体系:量化“懂你”的程度
- 进展体现在新兴基准测试的开发:KnowMe,RespondtoMe专注于评测模型“动态用户画像构建”和个性化响应能力;ECHO从“回声”的比喻出发,评估AI聊天机器人对用户个性的模仿能力;更进一步,前文提到的DigitalTwins基准通过评估模型模拟用户“行为链”的能力,将评测推向更深的认知层面。
4、终极愿景的雏形
虽然主要用于合成角色,但斯坦福著名的"虚拟小镇"项目,生动地展示了个性化Persona的未来潜力:创建拥有记忆、能够自主规划和反思的智能体。这为实现真正意义上、具备长期记忆和内在世界的“数字孪生”提供了宝贵的启示和技术蓝图。
综上,Persona赋予LLM以“身份”,从宏观群体特点到微观个人特质,目标是在交互中营造更真实的人格化体验。但不同类型Persona对应不同技术瓶颈:群体Persona要纠偏刻板印象,角色Persona要获取深度角色知识,个性化Persona则强调在线学习和隐私安全。这些挑战贯穿数据、算法和评测全流程,成为角色扮演大模型领域的核心研究方向。
Persona的评价基准
如果说Persona是赋予LLM灵魂的艺术,那么评测基准就是衡量其灵魂深度和一致性的科学。没有客观、可量化的评测,角色扮演能力的提升便无从谈起。近年来,该领域的评测体系已从早期的简单对话匹配,迅速演进为一个多维度、多层次的综合性评估矩阵,旨在从各个角度剖析Persona的塑造效果。
1、角色保真度与一致性
此维度主要面向角色型Persona。
- 核心问题:模型在多大程度上忠实、且持续地复现了一个特定角色?
- 核心目标:评估模型对角色知识的准确性、人格的忠实度和行为的长期一致性。
方法论与代表性基准:
综合性能力基准:这是目前的主流。RoleLLM开创性地提出了包含知识、风格、一致性等多维度的评测框架。在其基础上,CharacterBench以其巨大的规模和全面的维度,已成为业界公认的“黄金标准”之一,而CharacterEval则填补了中文角色评测基准的空白。这些基准通常采用“给定角色卡片->多轮对话->多维度打分”的模式。最新的 CoSER 将评测对象扩展至 771 本小说中的 17 966 个角色,并引入Given‑CircumstanceActing场景,进一步检验复杂剧情中的角色一致性
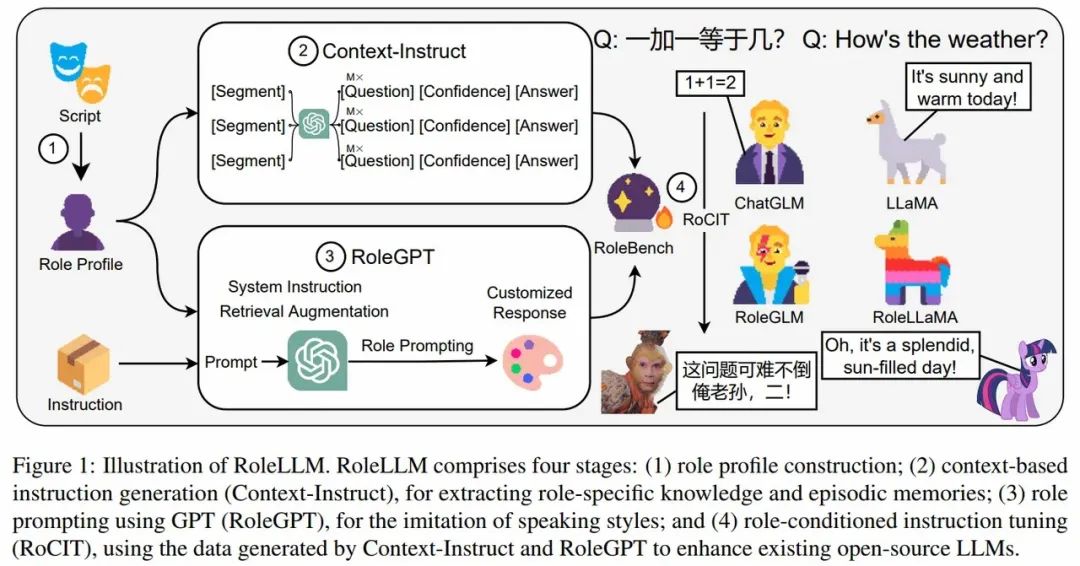
RoleLLM

CharacterBench

CharacterEval

CoSER
创新性评估方法:为了更深入地探测人格,InCharacter独创了“心理访谈”方法,通过专业的心理学量表来评估模型的人格忠实度,实现了从“行为模仿”到“人格对齐”的评测跨越。ROLETHINK进一步要求模型生成第一人称“内心独白”,用黄金/银标两套参考文本量化动机与价值观一致性。

InCharacter

ROLETHINK
面向前沿挑战的专项评测:随着研究深入,更复杂的评测应运而生。TimeChara专注于评测角色在特定时间点上的知识准确性(例如,《哈利·波特》第三部中的斯内普不应知道最终结局),解决了“时间错乱”的幻觉问题。而BookWorld则将评测场景从单人对话扩展到多智能体社会,评估模型在一整个虚拟世界中维持角色设定的能力。

TimeChara

BookWorld
2、群体倾向性与推理能力
此维度主要面向群体型Persona,关注其作为“双刃剑”的正反两面效应。
核心目标:量化角色设定所引入的社会偏见与刻板印象,并评估其对模型推理能力的潜在影响。
方法论与代表性基准:
风险面:
- 偏见与毒性量化:这是评测的重中之重。BiasRunsDeep通过精心设计的问题,揭示了模型在Persona提示下根深蒂固的“内隐偏见”。CoMPosT则专注于量化“漫画化”倾向,即模型对群体刻板印象的过度夸张。这些基准的核心方法是通过对比有无Persona提示的输出差异,来分离出角色设定带来的负面影响。

BiasRunsDeep

CoMPosT
机遇面:
- 推理能力增益评估:ExpertPrompting等研究证明,为LLM分配合适的“专家”角色,能显著提升其在特定领域的零样本推理能力。这类评测通常包含一系列专业领域的推理任务,用于检验不同角色设定对任务完成度的增益效果。
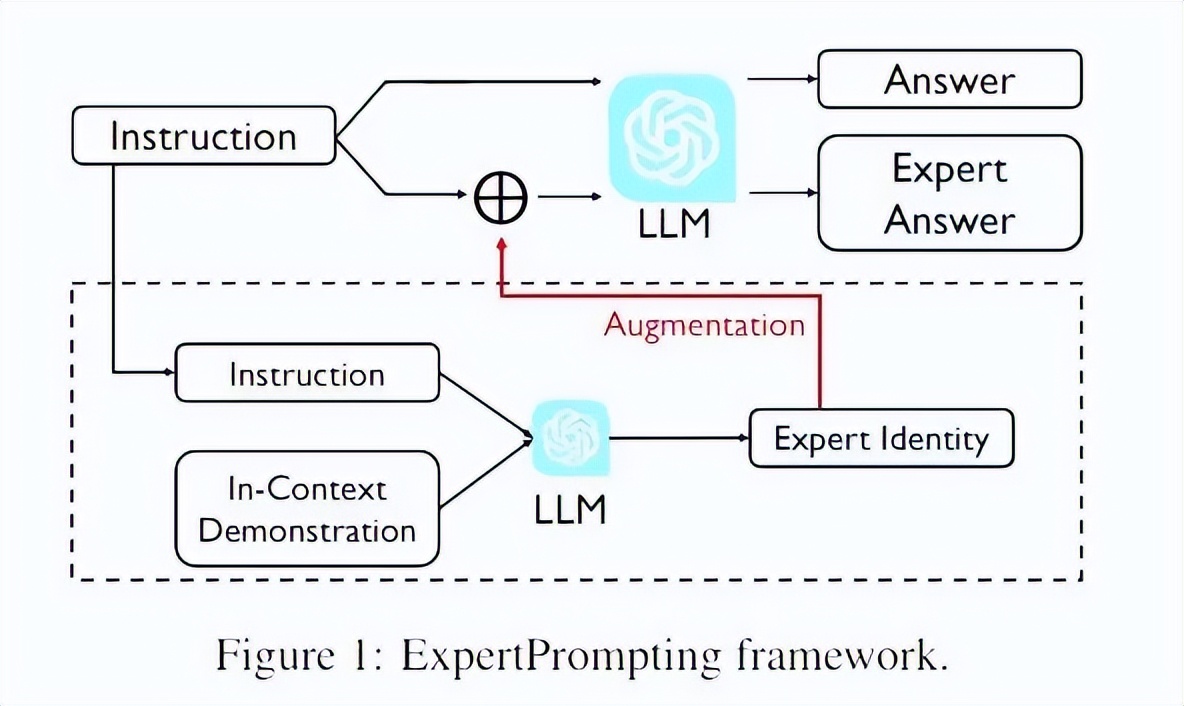
ExpertPrompting
3、个性化对齐与动态追踪
此维度面向个性化Persona,因其“评测目标”本身(即用户)是动态变化的,所以评测难度最大。
核心目标:评估模型学习、记忆、更新和模仿特定用户个人特征的能力。
方法论与代表性基准:
行为模拟与“数字孪生”评估:
- 评测模型能否“像你一样行动”。HowFarareLLMsfromBeingOurDigitalTwins?是此方向的代表,它设计了复杂的“行为链”任务(如“模拟用户完成一次购物决策”),来检验模型对特定用户决策模式的模拟准确度。

HowFarareLLMsfromBeingOurDigitalTwins?
记忆与画像更新评估:
- 评测模型能否“记住你的一切”。Know Me, Respond to Me是经典的长期记忆评测基准,专注于检验模型在多轮对话中读取、保持并动态更新用户画像的能力,即能否随着新信息的注入持续修正对用户的认知。PersonaLens 则将评测扩展到“任务型对话”场景,引入LLM‑模拟用户与LLM‑Judge双代理框架,同时衡量个性化质量与任务完成度。

Know Me, Respond to Me
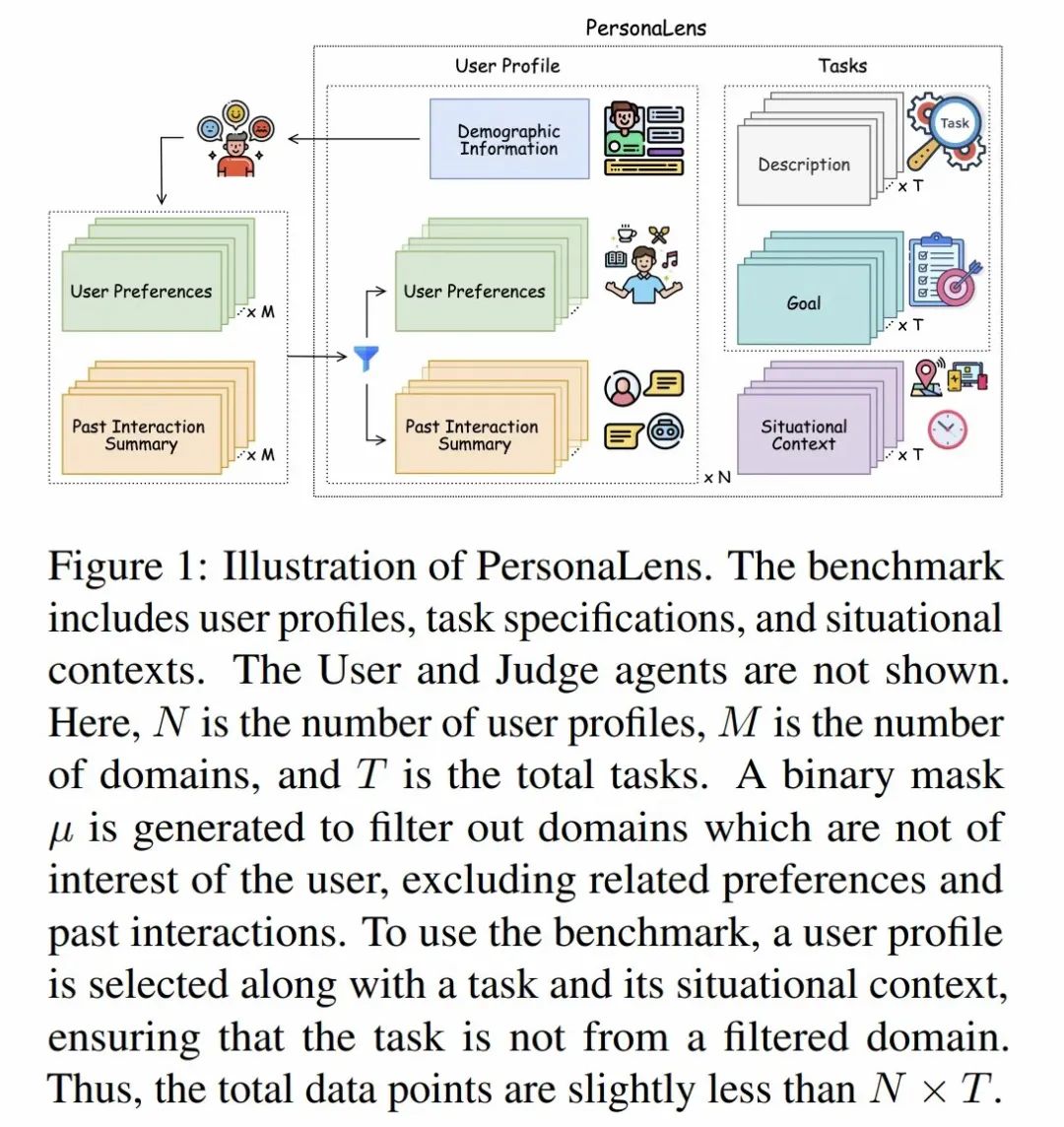
PersonaLens
风格对齐与“回声”测试:
- 评测模型能否“像你一样说话”。HowWellCanLLMsEchoUs?通过量化模型回复与用户自身语言风格的相似度,来评估其“模仿”能力。这些评测的实现,离不开大规模真实个性化对话数据集提供的丰富养料。

HowWellCanLLMsEchoUs?
4、社会与认知智能
此维度超越了语言和知识本身,深入到类人智能的核心,评估Persona背后是否蕴含了真正的社会认知能力。
核心目标:评估模型在社交场景下的同理心、社交性以及对他人心智状态的推理能力。
方法论与代表性基准:
社交能力评估:SocialBench是评估角色对话代理社交性的常用基准,涵盖了同理心、观点接纳等多个指标。而SOTOPIA则代表了更前沿的交互式评估范式,它构建了一个多智能体社会环境,让模型在其中通过互动完成复杂的社交目标,评测其在动态博弈中的社交智慧。

SocialBench

SOTOPIA
心理理论(ToM)评估:OpenToM是一个全面的ToM评测基准,它通过一系列经典的“错误信念”任务,来检验模型是否具备推测他人所思所想(哪怕是错误想法)的能力,这是实现深度共情的关键。
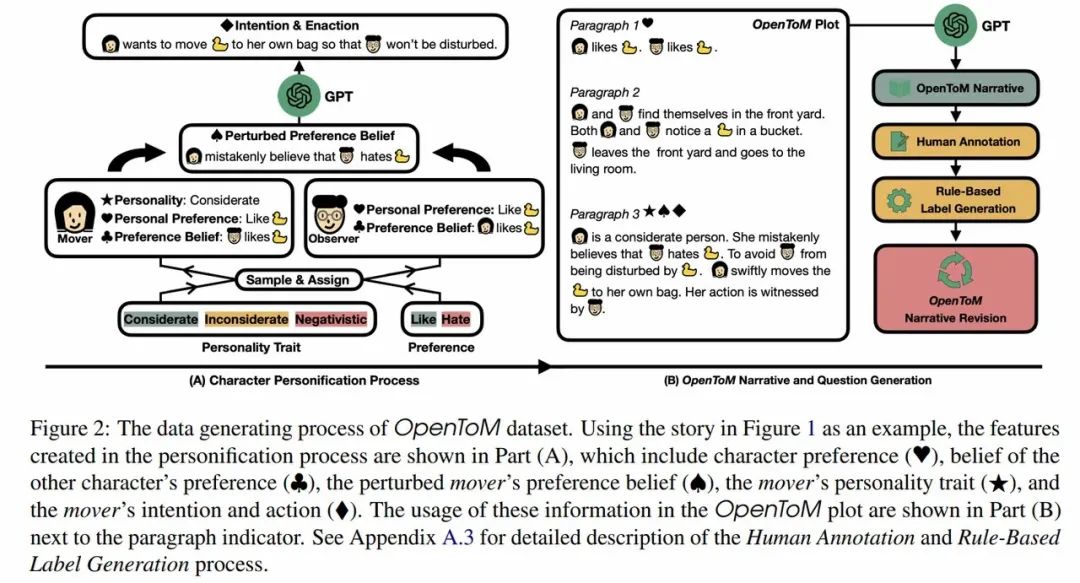
OpenToM
心理学量表应用:虽然MBTI、大五人格等传统心理量表被广泛用于验证Persona,但研究也警示,其结果高度依赖提示词,稳定性存疑,需谨慎解释。
5、综合性与对抗性评测
为了全面评估模型的综合实力并推动技术迭代,整合多个维度的“大一统”基准和排行榜应运而生。
核心目标:在一个统一的平台上,对模型的角色扮演综合能力进行排名,并测试其在复杂、对抗性环境下的鲁棒性。
方法论与代表性基准:
综合性竞技场:RPGBENCH将LLM置于“角色扮演游戏引擎”的设定中,要求模型同时扮演好游戏主持人和非玩家角色,是对其综合能力的极限考验。CharacterBox则在文本虚拟世界中评估模型的长期规划和互动能力。

RPGBENCH

CharacterBox
公开排行榜:许多研究机构和企业(如Boson等)基于这些综合基准建立了公开的排行榜,促进了角色扮演领域的良性竞争和技术标准化。
总的来说,多元评测基准从语言风格一致性、知识正确性、人格连贯性、社会偏好等多个维度,为角色扮演模型的Persona塑造水平提供客观诊断依据。这些评测推动研究者不断改进方法,以期模型在不同Persona下都能表现出可信、一贯且合乎期望的行为。
Persona的优化方法
要将一个通用LLM塑造为特定Persona,研究者们已经发展出一套层次分明、相辅相成的技术“武库”。这些方法如同一个金字塔,从底层最灵活、成本最低的提示工程,到中层需要深度数据驱动的参数微调和强化学习,再到顶层改变模型核心运作方式的架构革新。实践中,最先进的角色扮演系统往往是这些技术的有机组合。
1、提示工程(PromptEngineering)
这是最直接、最灵活、成本最低的一层,它利用LLM强大的上下文学习能力,在不改变任何模型参数的情况下引导其进入角色。
核心思想:通过精心设计的Prompt来激活模型内部已经存在的、与特定角色相关的知识和行为模式。
技术路径与代表性研究:
- 基础技巧:身份与示范。最简单的是系统级身份提示(如“你是一个乐观开朗的小学老师”)。更有效的是提供少量对话范例的Few-Shot示范,让模型通过模仿快速掌握风格。
- 能力增强:用于推理的角色扮演。研究发现,角色扮演不仅关乎风格,更能提升模型的核心能力。BetterZero-ShotReasoningwithRole-PlayPrompting和ExpertPrompting等工作证明,让模型先代入“领域专家”的角色,能显著提升其在复杂推理任务上的准确率,这为提示工程开辟了功能性的新用途。

BetterZero-ShotReasoningwithRole-PlayPrompting

ExpertPrompting
- 鲁棒性提升:多专家集成。为了克服单个提示的不稳定性,Multi-expertPrompting提出了一种集成策略,即同时激活模型内部的多个“专家”人格,对同一问题进行多角度回答后综合,从而提升响应的可靠性和安全性。

Multi-expertPrompting
- 自适应Prompt重写:利用小型LLM对用户请求进行自动改写,使其自然贴合目标Persona,减少人工prompt调参,并在跨任务迁移中保持一致风格。
提示工程的优劣势:
- 优势:极其灵活,成本极低,无需训练,可快速迭代测试。
- 劣势:效果不稳定,高度依赖提示的措辞技巧,且难以实现深层次、长周期的角色一致性。
2、参数微调(Fine-tuning)
如果说提示工程是“临时指导”,那么微调就是将Persona“刻进”模型参数中,实现更稳定、更深度的人格固化。
核心思想:使用特定角色的高质量数据对预训练模型进行二次训练,使其“专业化”于扮演该角色。
技术路径与代表性研究:
监督式微调(SupervisedFine-Tuning):这是最主流的方法。Character-LLM等工作通过收集或构建特定角色的对话、故事数据进行SFT,显著提升了角色语言风格的保真度。

Character-LLM
这里列出几个拟人化数据增强策略:
- 角色卡反向生成:核心思路是为海量无身份的真人对话,反向工程出角色设定。我们不再是“从人设到对话”,而是训练一个模型“从对话到人设”,让它读完一段对话后,自动生成一个合情合理的角色卡。这种方法能快速为真实语料赋予可用的训练标签,但其最大风险在于信息偏差:如果模型生成的角色卡没能捕捉到对话中的关键隐含信息(如“姐弟”关系),以此数据训练出的角色就可能学会过度“脑补”,破坏一致性。
- 分阶段风格迁移:此策略将训练分为两步,如同先浸泡食材,再下锅烹饪。第一阶段,让基础模型在海量真实对话数据中进行短暂的、大规模的“风格预训练”,使其充分吸收“人话”的语感和节奏。第二阶段,再用这个“泡过澡”、风格更自然的模型去进行标准的角色数据微调。这种方法的核心权衡是用“智商”换“情商”:它能显著提升模型的拟人度,但代价是可能轻微削弱模型在逻辑和知识任务上的严谨性。
- 基于改写器的数据合成pipeline:这套方案的构思最为精妙,它利用了模型的一个特性:将“人话”改写成刻板的“AI话”很容易。我们便利用这一点,先让大模型生成海量的(真人句->AI句)数据对。然后,我们将输入和输出反过来,用这些数据训练一个专门的“拟人化改写器”。最后,用这个改写器去批量处理我们合成的、风格较为刻板的角色对话,系统性地为其注入生动和真实感。此方案的成功完全依赖于数据质量,必须通过严格的自动化流程,剔除改写中产生的语义错误和与人设不符的风格,才能确保最终效果。
数据策略:拥抱大规模合成数据。由于高质量的人工标注数据昂贵且稀缺,大规模合成数据已成为新范式。像下图中的OpenCharacter等研究展示了通过模型自己生成海量、多样化的Persona数据来进行微调,能够训练出高度可定制化的角色扮演模型。

OpenCharacter
参数高效微调(
Parameter-EfficientFine-Tuning,PEFT):为了解决为每个角色微调完整模型的巨大成本,PEFT技术(特别是LoRA)被广泛应用。像Neeko提出的动态LoRA方法是其中的佼佼者,它为每个角色学习一个极轻量的“适配器”,使得单个基础模型能够通过加载不同适配器,在数百个角色间实现低成本、高效率的快速切换。

Neeko
参数微调的优劣势:
- 优势:角色保真度和一致性远超提示工程,人格更稳固。
- 劣势:需要大量高质量数据,成本高昂,且容易导致“灾难性遗忘”,损害模型的通用能力。
3、强化学习(ReinforcementLearning)
在SFT赋予模型基础能力后,强化学习(RL)则像一位雕塑家,对模型的行为进行精雕细琢,使其更符合人类期望的、更抽象的特质(如“更有趣”、“更安全”)。
核心思想:将“好的角色扮演”定义为一个奖励函数,然后利用RL算法(如PPO、DPO)最大化这个奖励,从而优化模型的行为策略。
技术路径与代表性研究:
奖励模型的设计:这是RL成功的关键。RAIDEN-R1创新地引入了“可验证的奖励函数”,以确保奖励信号的可靠性,从而有效提升了模型的角色意识。ChARM则提出了“基于角色的动作自适应奖励建模”,对对话中的每一步行动进行打分,实现了更精细的行为控制。

RAIDEN-R1
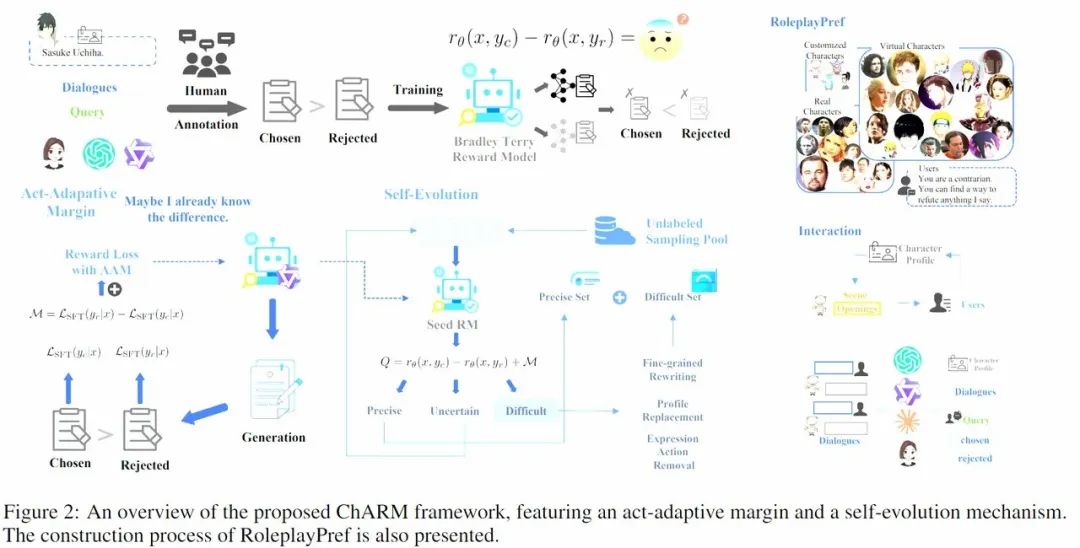
ChARM
与人类反馈的结合(RLHF):将人类的偏好作为最终的奖励来源,是确保Persona符合社会规范和伦理的黄金标准。经典的“有帮助且无害的AI助手”就是通过RLHF,根据人类的反馈不断调整其行为,使其无限趋近于理想人格。
强化学习的优劣势:
- 优势:能够优化无法通过静态数据直接学习的抽象品质(如安全性、趣味性、共情能力),实现更细腻的行为对齐。
- 劣势:奖励函数的设计极具挑战性,训练过程复杂且不稳定,计算成本非常高。
4、架构革新
这是最根本、最具颠覆性的一层。它不再满足于模拟“行为”,而是尝试在模型架构层面模拟人类的记忆与认知机制,从根本上解决长期一致性等问题。
核心思想:为LLM增加显式的记忆模块或认知循环,使其能够像人一样积累经验、进行反思并据此规划未来行动。
技术路径与代表性研究:
里程碑:生成式智能体。斯坦福的“虚拟小镇”是该领域的开创性工作。它为每个智能体设计了“感知-储存-检索-反思-规划”的完整认知循环。智能体能将日常观察存入“记忆流”,定期“反思”形成高层认知,并在行动时“检索”相关记忆。这一架构使得智能体展现出惊人的长期一致性和可信的社会行为。
架构在对话中的应用:这一思想被迅速应用于对话场景。下图中提到的PsyMem通过为模型注入“细粒度心理档案”和显式记忆控制,实现了更深度的角色沉浸;还有之前提到的DEEPER则通过“定向人格提纯”架构,让模型能够动态地更新和利用用户记忆,更好地服务于个性化场景。

PsyMem

DEEPER
逻辑与知识的结构化:为了确保角色行为的合理性,研究者开始探索如何将知识与逻辑内嵌于架构中。ERABAL提出的“边界感知学习”训练模型遵守不同角色的信息边界,避免“穿模”。CodifyingCharacterLogic则尝试将角色的决策逻辑编码,防止其做出违背核心动机的行为。而Self-Alignment思想则让模型首先自我生成一套角色“宪法”,然后在后续交互中严格遵循,实现了内在逻辑的自洽。

ERABAL

CodifyingCharacterLogic

Self-Alignment
架构革新的优劣势:
- 优势:从根本上解决了长期一致性问题,能产生更具深度和涌现性的拟人行为。
- 劣势:极大地增加了模型架构的复杂度和推理成本,是当前研究的最前沿。
综合运用以上技术:
提升Persona能力并非单选题,而是需要根据具体场景和成本预算,打出一套漂亮的“组合拳”。未来的顶尖角色扮演模型,极有可能是一个以高效微调模型为基座,通过长期记忆模块维持一致性,利用检索增强确保知识准确性,再经由强化学习进行安全和风格对齐,最终通过精巧的提示与用户进行交互的复杂而优雅的系统。
四、总结与未来工作
如今,角色扮演大模型正推动AI落地形态从「功能性工具」向「人格化交互体」跨越——它赋予算法血肉与身份,让AI能以千面角色与人对话,既为研发者开辟「从虚构角色到真实群体」的人格模拟创意富矿,也锚定全新挑战:需在「用Persona设计增强体验」的人格魅力构建,与「规避偏见、失控风险」的伦理责任间找到平衡。
而这一平衡的达成,既依赖技术脉络的清晰梳理(涵盖交互叙事/写实对话两大方向、角色型/群体型/个性化的人格设计方法、角色一致/群体倾向等测评基准、提示工程/参数微调/强化学习的优化路径),更需要工具链设计的精准承接,当理论向实际应用(如角色管理系统、人设编辑工具)转化时,工具链的设计细节对开发者体验与系统实用性至关重要。这一环节虽未直接涉及模型能力的提升,却决定了技术落地的效率与灵活性,可从三个层面展开讨论:
首先,在提示词管理框架的选择上,轻量级模板引擎(如Jinja)相比重型工作流框架(如LangChain)更适配专业角色管理场景。Jinja通过{{变量}}与条件逻辑(如{%if人设特征%})支持开发者对角色特征进行精细化定义,同时其简洁语法便于与代码编辑器集成,实现人设模板的快速迭代与版本控制——这对于高频调整角色设定的场景(如交互叙事中的多角色并行管理)尤为关键。相比之下,LangChain的高层API虽简化了复杂工作流,但会削弱对提示词细节的直接控制,更适合端到端应用而非精细化的角色模板设计。

其次,现有工具(如字节跳动的PromptPilot)的设计理念值得借鉴:其实时渲染功能(编辑变量时同步预览最终提示词)可迁移至角色对话场景,通过分屏布局帮助开发者即时校验角色表达的一致性;带版本控制的模板库与变量schema校验机制,则能降低角色设定的复用成本与错误率(如确保{{记忆.时间}}为有效格式),这些特性可与角色卡片(charactercard)系统结合,进一步提升工具专业性。

最后,角色管理工具的组件设计需遵循“核心突出、次要可压缩”原则:人设(persona)作为核心模块,应保留完整的特征编辑界面(如性格、背景、语言风格);记忆(memory)与存储(storage)可采用折叠面板,仅展示关键信息(如最近交互、存储状态);模态交互(modal)等附加功能则通过标签页切换激活,避免主界面信息过载。这种设计既符合开发者工具的高效性需求,也为多角色并行管理提供了灵活性。

基于上述工具链设计思路,我们正在实践中开发一套面向开发者的「MaggiePersonaEngine」人设模板系统,旨在将角色塑造的技术流程转化为可操作的工具界面,实现从人设定义到模型调用再到效果测评的全链路管理。期待AI角色扮演在未来的游戏创作中发挥越来越重要的作用。
参考文献
[1]NafisSadeq,ZhouhangXie,ByungkyuKang,PraritLamba,XiangGao,JulianMcAuley.MitigatingHallucinationinFictionalCharacterRole-Play.eprintarXiv:2406.17260
[2]Chen,Nuo;Wang,Yan;Jiang,Haiyun;Cai,Deng;Li,Yuhan;Chen,Ziyang;Wang,Longyue;Li,Jia.LargeLanguageModelsMeetHarryPotter:ABilingualDatasetforAligningDialogueAgentswithCharacters.eprintarXiv:2211.06869
[3]YunfanShao,LinyangLi,JunqiDai,XipengQiu.Character-LLM:ATrainableAgentforRole-Playing.eprintarXiv:2310.10158
[4]XilongCheng,YunxiaoQin,YutingTan,ZhengnanLi,YeWang,HongjiangXiao,YuanZhang.PsyMem:Fine-grainedpsychologicalalignmentandExplicitMemoryControlforAdvancedRole-PlayingLLMs.eprintarXiv:2505.12814
[5]XintaoWang,HengWang,YifeiZhang,XinfengYuan,RuiXu,Jen-tseHuang,SiyuYuan,HaoranGuo,JiangjieChen,ShuchangZhou,WeiWang,YanghuaXiao.CoSER:CoordinatingLLM-BasedPersonaSimulationofEstablishedRoles.eprintarXiv:2502.09082
[6]ZekunMooreWang,ZhongyuanPeng,HaoranQue,JiahengLiu,WangchunshuZhou,YuhanWu,HongchengGuo,RuitongGan,ZehaoNi,JianYang,ManZhang,ZhaoxiangZhang,WanliOuyang,KeXu,StephenW.Huang,JieFu,JunranPeng.RoleLLM:Benchmarking,Eliciting,andEnhancingRole-PlayingAbilitiesofLargeLanguageModels.eprintarXiv:2310.00746
[7]JinfengZhou,YongkangHuang,BosiWen,GuanqunBi,YuxuanChen,PeiKe,ZhuangChen,XiyaoXiao,LibiaoPeng,KuntianTang,RongshengZhang,LeZhang,TangjieLv,ZhipengHu,HongningWang,MinlieHuang.CharacterBench:BenchmarkingCharacterCustomizationofLargeLanguageModels.eprintarXiv:2412.11912
[8]QuanTu,ShilongFan,ZihangTian,RuiYan.CharacterEval:AChineseBenchmarkforRole-PlayingConversationalAgentEvaluation.eprintarXiv:2401.01275
[9]XintaoWang,YunzeXiao,Jen-tseHuang,SiyuYuan,RuiXu,HaoranGuo,QuanTu,YayingFei,ZiangLeng,WeiWang,JiangjieChen,ChengLi,YanghuaXiao.InCharacter:EvaluatingPersonalityFidelityinRole-PlayingAgentsthroughPsychologicalInterviews.eprintarXiv:2310.17976
[10]HongzhanChen,HehongChen,MingYan,WenshenXu,XingGao,WeizhouShen,XiaojunQuan,ChenliangLi,JiZhang,FeiHuang,JingrenZhou.SocialBench:SocialityEvaluationofRole-PlayingConversationalAgents.eprintarXiv:2403.13679
[11]HaonanZhang,RunLuo,XiongLiu,YuchuanWu,Ting-EnLin,PengpengZeng,QiangQu,FeitengFang,MinYang,LianliGao,JingkuanSong,FeiHuang,YongbinLi.OmniCharacter:TowardsImmersiveRole-PlayingAgentswithSeamlessSpeech-LanguagePersonalityInteraction.eprintarXiv:2505.20277
[12]YanqiDai,HuanranHu,LeiWang,ShengjieJin,XuChen,ZhiwuLu.MMRole:AComprehensiveFrameworkforDevelopingandEvaluatingMultimodalRole-PlayingAgents.eprintarXiv:2408.04203
[13]YitingRan,XintaoWang,TianQiu,JiaqingLiang,YanghuaXiao,DeqingYang.BookWorld:FromNovelstoInteractiveAgentSocietiesforCreativeStoryGeneration.eprintarXiv:2504.14538
[14]XiaoyangWang,HongmingZhang,TaoGe,WenhaoYu,DianYu,DongYu.OpenCharacter:TrainingCustomizableRole-PlayingLLMswithLarge-ScaleSyntheticPersonas.eprintarXiv:2501.15427
[15]TaoGe,XinChan,XiaoyangWang,DianYu,HaitaoMi,DongYu.ScalingSyntheticDataCreationwith1,000,000,000Personas.eprintarXiv:2406.20094
[16]Young-JunLee,DokyongLee,JunyoungYoun,KyeongjinOh,ByungsooKo,JonghwanHyeon,Ho-JinChoi.Stark:SocialLong-TermMulti-ModalConversationwithPersonaCommonsenseKnowledge.eprintarXiv:2407.03958
[17]VinaySamuel,HenryPengZou,YueZhou,ShreyasChaudhari,AshwinKalyan,TanmayRajpurohit,AmeetDeshpande,KarthikNarasimhan,VishvakMurahari.PersonaGym:EvaluatingPersonaAgentsandLLMs.eprintarXiv:2407.18416
[18]JunruLu,JiazhengLi,GuodongShen,LinGui,SiyuAn,YulanHe,DiYin,XingSun.RoleMRC:AFine-GrainedCompositeBenchmarkforRole-PlayingandInstruction-Following.eprintarXiv:2502.11387
[19]ShashankGupta,VaishnaviShrivastava,AmeetDeshpande,AshwinKalyan,PeterClark,AshishSabharwal,TusharKhot.BiasRunsDeep:ImplicitReasoningBiasesinPersona-AssignedLLMs.eprintarXiv:2311.04892
[20]AmeetDeshpande,VishvakMurahari,TanmayRajpurohit,AshwinKalyan,KarthikNarasimhan.ToxicityinChatGPT:AnalyzingPersona-assignedLanguageModels.eprintarXiv:2304.05335
[21]MyraCheng,TizianoPiccardi,DiyiYang.CoMPosT:CharacterizingandEvaluatingCaricatureinLLMSimulations.eprintarXiv:2310.11501
[22]DoXuanLong,KenjiKawaguchi,Min-YenKan,NancyF.Chen.AligningLargeLanguageModelswithHumanOpinionsthroughPersonaSelectionandValue–Belief–NormReasoning.eprintarXiv:2311.08385
[23]Yun-ShiuanChuang,KrirkNirunwiroj,ZachStuddiford,AgamGoyal,VincentV.Frigo,SijiaYang,DhavanShah,JunjieHu,TimothyT.Rogers.BeyondDemographics:AligningRole-playingLLM-basedAgentsUsingHumanBeliefNetworks.eprintarXiv:2406.17232
[24]ChengLi,MengzhouChen,JindongWang,SunayanaSitaram,XingXie.CultureLLM:IncorporatingCulturalDifferencesintoLargeLanguageModels.eprintarXiv:2402.10946
[25]MingqianZheng,JiaxinPei,LajanugenLogeswaran,MoontaeLee,DavidJurgens.When"AHelpfulAssistant"IsNotReallyHelpful:PersonasinSystemPromptsDoNotImprovePerformancesofLargeLanguageModels.eprintarXiv:2311.10054
[26]AlirezaSalemi,ShesheraMysore,MichaelBendersky,HamedZamani.LaMP:WhenLargeLanguageModelsMeetPersonalization.eprintarXiv:2304.11406
[27]JingshengGao,YixinLian,ZiyiZhou,YuzhuoFu,BaoyuanWang.LiveChat:ALarge-ScalePersonalizedDialogueDatasetAutomaticallyConstructedfromLiveStreaming.eprintarXiv:2306.08401
[28]EhsanLotfi,MaximeDeBruyn,JeskaBuhmann,WalterDaelemans.PersonalityChat:ConversationDistillationforPersonalizedDialogModelingwithFactsandTraits.eprintarXiv:2401.07363
[29]JaewooAhn,YedaSong,SangdooYun,GunheeKim.MPCHAT:TowardsMultimodalPersona-GroundedConversation.eprintarXiv:2305.17388
[30]ZheniZeng,JiayiChen,HuiminChen,YukunYan,YuxuanChen,ZhenghaoLiu,ZhiyuanLiu,MaosongSun.PersLLM:APersonifiedTrainingApproachforLargeLanguageModels.eprintarXiv:2407.12393
[31]AiliChen,ChengyuDu,JiangjieChen,JinghanXu,YikaiZhang,SiyuYuan,ZulongChen,LiangyueLi,YanghuaXiao.DEEPERInsightintoYourUser:DirectedPersonaRefinementforDynamicPersonaModeling.eprintarXiv:2502.11078
[32]GonçaloHoradeCarvalho,OscarKnap,RobertPollice.Show,Don'tTell:EvaluatingLargeLanguageModelsBeyondTextualUnderstandingwithChildPlay.eprintarXiv:2407.11068
[33]BowenJiang,ZhuoqunHao,Young-MinCho,BryanLi,YuanYuan,SihaoChen,LyleUngar,CamilloJ.Taylor,DanRoth.KnowMe,RespondtoMe:BenchmarkingLLMsforDynamicUserProfilingandPersonalizedResponsesatScale.eprintarXiv:2504.14225
[34]ManTikNg,HuiTungTse,Jen-tseHuang,JingjingLi,WenxuanWang,MichaelR.Lyu.HowWellCanLLMsEchoUs?EvaluatingAIChatbots'Role-PlayAbilitywithECHO.eprintarXiv:2404.13957
[35]RuiLi,HemingXia,XinfengYuan,QingxiuDong,LeiSha,WenjieLi,ZhifangSui.HowFarareLLMsfromBeingOurDigitalTwins?ABenchmarkforPersona-BasedBehaviorChainSimulation.eprintarXiv:2502.14642
