现在AI视频都发展到哪一步了?普通人怎么利用AI视频赚钱?
探索更多不打工也能挣钱的方式。

也许你会好奇,从23年初出圈的史密斯吃意大利面的惊悚,到24年如今层出不穷的AI视频新应用,这一两年发展特别火热的AI视频现在究竟发展的怎么样了?

AI真的像网上很多的媒体平台说的那样神通广大,要替代掉导演和演员,能让每个人都能成为一次导演吗?
关于这些问题,我想在今天的这期内容里,向大家一一说明:
AI视频现在发展的状况,它有什么上限和限制,现在国内外的主流AI视频应用有哪些?
以及大家可能很感兴趣的,关于在这个领域里,还有没有那么一点普通人可以赚到钱的机会?

你好,我是浩祥,欢迎来到新个体时代频道,这个频道主要是分享普通人如何不打工也能挣钱的方式的探讨,
如果有兴趣的话可以点一下关注,那废话不多说,我们直接开始。
一、AI视频基础概念
首先,要谈到AI视频,我们就必须要先了解AI视频主流的三种生成方式:
文生视频,图生视频和视频转视频。
其中文生视频和图生视频是目前应用最广泛的两种生成方式,也就是我们广义上理解的AI生成视频。
1、文生视频
文生视频是指,你输入一段提示词给到AI,AI根据你的提示词来生成视频。

这样生成的视频有几点好处:
①可以将某些甲方难以理解的需求,比如五彩斑斓的黑,借助AI的脑洞帮你快速生成一张参考的效果图片。
②可以根据提示词的不同,让AI帮你创作这个主体的其他风格可能会是什么样子的?能够帮助你发散思维形成创意。
③随机性强,虽然这一点是个双刃剑,但如果运用的好的话,还是能够给你带来不少帮助的。
2、图生视频
而图生视频呢,是指你提供给AI一张图片,加上你的提示词,AI根据你给的图片和提示词,共同结合来生成视频。

我们可以看到,图生视频比文生视频多了一个添加图片的功能,
我们可以把它理解为让AI有了参考生成对象,可以很好的起到限制AI生成随机性,让AI朝着你的参考图稳定出风格类似的图的效果。
图生视频有几点好处:
①可控性较强,相比起文生视频的随机性,图生视频能够比较好的把控出图风格,增强了稳定性。
②画面一致性强,比如现在我有一张男士在奇幻背景的蘑菇森林头戴VR设备的图片,想让它变成视频动起来。

如果是文生视频的话,我需要很细致的描述男士的衣着相貌,空间布局,VR设备形状,就这还生成不出来跟原有图片一模一样的布局。
但你若是给到AI这么一个图片,然后加上描述语的话,那么AI就可以很好的将原有图片的空间布局和人物特征进行保留,再进行视频生成的。
所以应用到商业化场景,几乎全部都是用图生视频的。
3、视频转视频
至于视频转视频,目前这一块声量不大,只有几个平台在做,更多是属于AI的工具性应用而非前两种的AI生成。
如果用比喻的话就是,视频转视频目前是AI视频编辑的范畴,
但是文生视频和图生视频,则属于AI视频生成的范畴,也是我们现在广义上讲的AI视频了。
但是视频转视频这一块是我认为AI视频应用最成熟的部分了。
简单来讲就是把原有的视频素材用AI来进行魔改,将原有视频里面的元素进行更替,画面整体风格转绘等。

比如涂抹区域实现人物衣服换装,将视频里的人物变成另一个人,亦或是视频换脸等,都属于这个范畴。
之前很火的郭德纲讲相声其实也是视频转视频的一类应用。
用更简单的话来总结一下的话就是,
文生视频是给你提供创意用的,
图生视频是让你更精细化操纵用的,
视频转视频则属于AI视频编辑范畴,是目前我个人认为应用最成熟落地的。
4、AI视频当前使用上限与限制
了解了AI视频生成方式主流的文生视频和图生视频后,
我们再来认识一下AI视频目前的一些使用上限和限制。
现在我们的AI生成视频,无论是国内还是国外,生成的视频都是按秒来计算,
目前市面上主流的AI生成视频工具都集中在4秒-10s左右。目前一次生成最长不超过10秒。
而且目前AI视频还存在几个技术难点,
第一,人物面部一致性还不够好。
不论是国内还是国外,现在的AI生成视频,虽然在某些方面生成出来的真人形象的视频非常地逼真,
但是一旦时间稍后面一点点,要么面庞开始形变,要么眼瞳发生形变。
这一点现在并没有能够很好的解决,虽然相比起23年的时候,有了突飞猛进的进步,但仍然还有很大的进步空间。

第二,AI生成的视频,里面的人物主体一旦运动幅度较大,就会出现某些视觉污染的现象。
比如,我们现在能看到的一些AI视频,
如果里面的人物是动作幅度很小的静态写真,那么就不太容易出现视觉污染的情况。
但若是人物一旦动起来,比如说跑步,那么生成出来的视频,就特别容易出现崩坏的情况。
这是目前所有的AI视频平台都存在的技术难点。
比如现在很多的AIGC达人,其实都喜欢用体操运动,花式平衡木运动等来测试AI视频平台的技术水平。

总的来讲,人物一致性,场景一致性,人物表演,动作交互,运动幅度这五个方面,
仍然是目前AI视频亟待解决的痛点问题。
所以,根据以上这两点情况,
要说AI视频真的已经发达到已经能够替代掉导演和演员的话,
其实还有不少的路要走,现在的AI视频,基本上是取代不了现在的影视行业视频工作流的。
它无法取代工作,而且对制作效率的提升也不是特别明显。
更多是在补一些分镜头的画面,或做特色创意的表现的时候,会更适合。
所以整体的AI视频,现在更多是一种先卫的测试科技,
但是距离真正的商业化落地还有些距离,
目前都是头部的几个技术达人在做有关的商业化落地案例。
以上,就是有关于AI视频目前的发展现状,上限和限制的内容。
接下来我们再来谈谈,国内外目前主流的AI视频生成的应用。
二、国外AI视频简评
1、RUNWAY(目前上限最高的最强王者)
要说在AI生成视频里,谁是目前当之无愧的老大哥?
毫无疑问的,作为首批公开推出的AI视频平台的Runway,对此非常的有话语权。

Runway的公司,曾经和Stability AI、CompVis两家一起合作开发出了大名鼎鼎的Stable diffuion模型。也就是我们现在俗称的SD,整个AI绘画圈就没有不知道的。
而Runway公司在AI视频领域最具代表性的,就是他们的视频生成模型Gen系列。

Gen1模型,视频到视频生成,主要针对于已有视频,对现有的影片素材进行替换,让用户可以输入文字指令就能更改影片中的物品颜色,图像风格,比如将视频风格变换成赛博风格,云雾风格,简笔画风格等。
Gen2模型,文字/图片生成视频,与Gen1不同,主要针对于还没有视频,仅通过文本/图片提示,就能生成4s的视频。甚至还能通过笔刷功能,独立控制视频中的某个区域进行变化。据传此版本还曾为《瞬息全宇宙》电影提供了技术支持。
Gen3 alpha模型,也就是最新的模型,可以根据文字/图片生成10s的视频,官方说是接下来即将发布的一系列最新模型的先锋军。就目前看来,在模型质量上还是目前所有AI视频平台里能用的NO.1,
生成时长:
Gen2模型生成4秒,可延长4秒。Gen3模型可选择生成5秒/10秒,目前还不支持延长。

优点:
①在写实(尤其是自然环境和近景特写方面)和科幻方面有更出色的表现,光影效果很好审美在线

②视频生成速度比较快,哪怕你是免费版,也基本上不会超过3分钟。
③抽象画面、特效部分很强,抽象艺术的视觉表现非常炸裂,比自己用AE做的好多了。

④视频生成文字,这一块是目前Runway格外出色的地方,比其他家的字体变形的情况不同,RunwayGen3,只需要把需要写的文字放到引号“”里面去就可以。不过目前只支持英文字。

⑤运动画笔功能非常好,像修图一样去修视频。
缺点:
①一次性积分,要想继续试验只能付费,没有其他家每天赠送积分的那套玩法。
②在动画动漫领域,整体表现都很差。
③全景镜头和中景镜头的话,人物效果差。
使用成本:
注册账号即可获得积分,我注册的时候是直接525个积分(据说是免费版送一次性125个积分,我的应该是还有注册账户初始送的400个积分。)。
可将积分用来免费尝试生成视频,每个生成视频的时长为4秒,每秒消耗5个积分。所以生成一个视频是20个积分。
免费版是一次性525个积分,付费版可每月计费日重置为625个积分。

可以换算一下,
如果是免费版,525积分可用Gen-2生成105秒视频。但是只能用Gen1和Gen2模型。
如果是付费版,那么就可以用Gen3模型,但是也更贵,10个积分一秒,算下来625积分只够你生成6个10秒视频(或12个5秒视频)。
积分消耗完可以付费购买,1美元100积分。
客观地说,确实挺贵的。

我理解的是,Runway走的路子,是和OpenAI一样,靠模型来赚钱。
这一点与其他家不同,其他家目前都是靠次数赚钱,生成的模型都是最新的。但是Runway是用行业内最强的表现来引导你用他们家模型才能生成如此效果。虽然这个业内最强实际上也就是矮个子里面挑将军罢了。

2、Luma AI的Dream machine(强调创意和分镜的银牌选手)
说完老大哥Runway后,接下来就是备受瞩目的LumaAI的Dream machine了,
Luma的特点就好像他们官网里提到的,比较擅长做这种比较有运镜感的镜头。

相比起其他的视频效果,Luma能有一点电影感的画面转场。
而Luma比较好的一点是,它的生成模型都是内置最新模型的,
而且免费用户每个月都能有30次的免费生成额度。付费点在于购买生成次数。
生成时长:
一次性生成5秒,生成后支持延长5秒。

优点:
①画面镜头感强,甚至可以说目前LUMA生成的视频是目前所有平台里面运镜、分镜做的最好的,最有电影感。

②支持120帧,由于帧率提升,一些慢镜头等都能做,视频也会显得更丝滑。
③上限足够,熟练应用的话,出的视频上限足够高能接近Sora演示效果。
④支持首尾帧融合功能,上传首、尾帧两张图片,就能自动填充过渡画面
缺点:
①等待时间巨长,免费版动辄几小时起步,能等到你天荒地老,即使是付费版也常有十几分钟都生成不了的情况。
②人物物体还是容易变形(不要相信说的人物一致性强的说法),如果有移动情况更容易崩坏。对于文字、标识的理解不够会变形。画面容易崩坏容易出现头尾相连等情况。
③与上限高对应的,下限也很低,如果不多调控几次掌握点水平的话,生成出来的视频效果还不如Pika和可灵等。
使用成本:
免费版每月30次生成。一次生成5秒视频。
付费版如下图所示:

3、Pika(写实性被秒杀,但是对于动画来说比较好用,还可以对口型)
24年年初的时候,Pika在我们国内声名鹊起,还记得当时都在传Pika的创始人励志故事。
一段马斯克当宇航员飞上天空的视频也大面积刷屏,这些都是Pika带给我的第一印象。

但是,从2023年12月底的出圈开始之后,一直到24年现在的8月份,PIKA都没有推出更新的模型来,
一直处于1.0模型的PIKA自然跟不上现在的第一梯队了,还整体处在对标RunwayGen2模型的地步。
生成时长:
每次生成3秒视频,花费10积分。可以花费15积分延长4秒。

优点:
①retry功能,能用一组提示词创造多个片段,点一下就能直接在同窗口生成多个视频,下方的预览条还能对比挑选。
②区域修改功能不错,可以通过框选区域,使该区域视频画面进行单独更改。比如框选人物眼部凭空给人物戴上墨镜等。
③口型同步功能,虽然作用不大,不过聊胜于无。
④3D和2D动画方面,相对还不错。
缺点:
①写实方面,人物面庞一致性等方面还不够好,处于Gen2级别的那种。
②模型老旧,现已跟不上第一梯队。

使用成本:
注册赠送250积分,每次生成3秒视频,花费10积分。可以花费15积分延长4秒。
利用初始赠送的积分,可以生成25个3秒视频。
一旦初始积分用完,每天赠送30积分,可每天生成3个视频。

值得一提的是,与PIKA齐名的还有一个Haiper,也是写实性不行但是动漫特别是迪士尼风格亮眼,它们两个实力相差不大,就不单独说了。
4、Stable video(有本地开源部署的SVD,和网页版的Stable video区分。)
国外AI视频模型的最后一个主流的应用,就是Stable video了。
它是由大名鼎鼎的Stable diffusion团队研发的文生/图生视频模型,有线上的Stable video版本和本地部署的Stable video diffusion版本两种。

这里我们先主要讲线上版本的这个Stable diffusion。
与其他家相对不同的一点是,我们输入提示词给Stable video后,Stable video会根据提示词,先生成4张图片供你选择,选择你中意的图片之后,再以这个图片为首帧开始生成视频。

生成时长:
10个积分生成4秒视频,暂不支持延长视频。

优点:
①在空间的稳定性(注意是空间,不是主体)一致性方面,效果相对出色。
②由它来生成的首帧图相对比较出色,可以用作其他视频的参考图。
缺点:
①一旦画面出现人物走动,形体移动等会动的情况,动的部分就容易画面崩了。

②由于整体的生成模型还是1.1版本,对标的Gen2,所以生成视频效果也是等同于Gen2,另外由于线上官网版本,和基于本地部署的Stable video diffusion不同,没有那么多的可扩展性,所以相对起来地位有点鸡肋。
使用成本:
注册后赠送初始40积分,文生视频生成1个视频需要11积分,图生视频生成1个视频需要10积分。
每天都会获得40积分。10美元500积分可以生成50个视频。现在已经从之前的每天150积分变成每天40积分了。这个是动态下降的。

三、国内AI视频简评
1、可灵(国产王者)
说完了上面4个国外AI视频产品,终于要说回我们国内的AI视频产品了。
目前,互联网上基本上说到国内AI生成视频的应用,就离不开“可灵”这个异军突起的国产王者选手了。

可灵kling大模型,属于快手研发的大模型应用,下载快影App,在AI创作——AI生视频里就能应用了。
它也有专门的网页端可以在线使用。
由于是快手出品,使用了大量的快手素材,所以在短视频方面会比起其他应用要更落地一些。
尤其在吃这个领域更是有精彩表现。

(备注:本视频为AI生成视频)
总体上讲,与前面的Runway和Luma AI强调的艺术性、电影级生成的定位不一样,
可灵还是更多服务于短视频的。
比如用可灵生成熊猫弹吉他、小猫吃泡面这种短视频效果就很好。

生成时长:
可以生成5秒/10秒视频,不过免费版用户只能生成5秒视频。视频延长功能也需要会员,可延长5秒。

优点:
①尤善吃播,在吃东西领域可灵的表现目前堪称最强王者。
②视频延长功能(需要购买会员)。对生成视频一键续写,和连续多次续写,最长可生成约3分钟视频。
缺点:
①之前免费的王者,现在也开始收费了,很多功能都需要开会员。
②精致度上,还需要提升。比如人物的面庞,物体的边缘,还是会有扭曲的情况。
使用成本:
注册赠送初始66灵感值,生成一个5秒视频要10灵感值。
生成一个视频2-5分钟。每天登陆送66灵感值。也就是每天可免费生成6条5秒视频。
付费购买灵感值的话,收费见下图:

2、字节即梦DREAMINA(国产银牌选手)
字节出品,算是国产AI视频领域里面的银牌选手,对中国元素和中国长相比较友好,但是其他生成效果一般,质量也不稳定,打不过可灵。

生成时长:
可选择3、6、9、12秒视频4个选项,限时优惠是每秒1积分(之前没优惠的时候是每秒4积分)

优点:
①赠送积分多,每天赠送的80积分可生成26条3秒视频。
缺点:
①在生成复杂场景时,往往会出现一些细节缺失或画面模糊的情况。这对于要求高精度和细节的创作者来说,是一个较大的缺点。

②很多功能都需要开会员。
使用成本:
免费用户每天登录送 80 积分(原先是60积分),且积分不会累积。
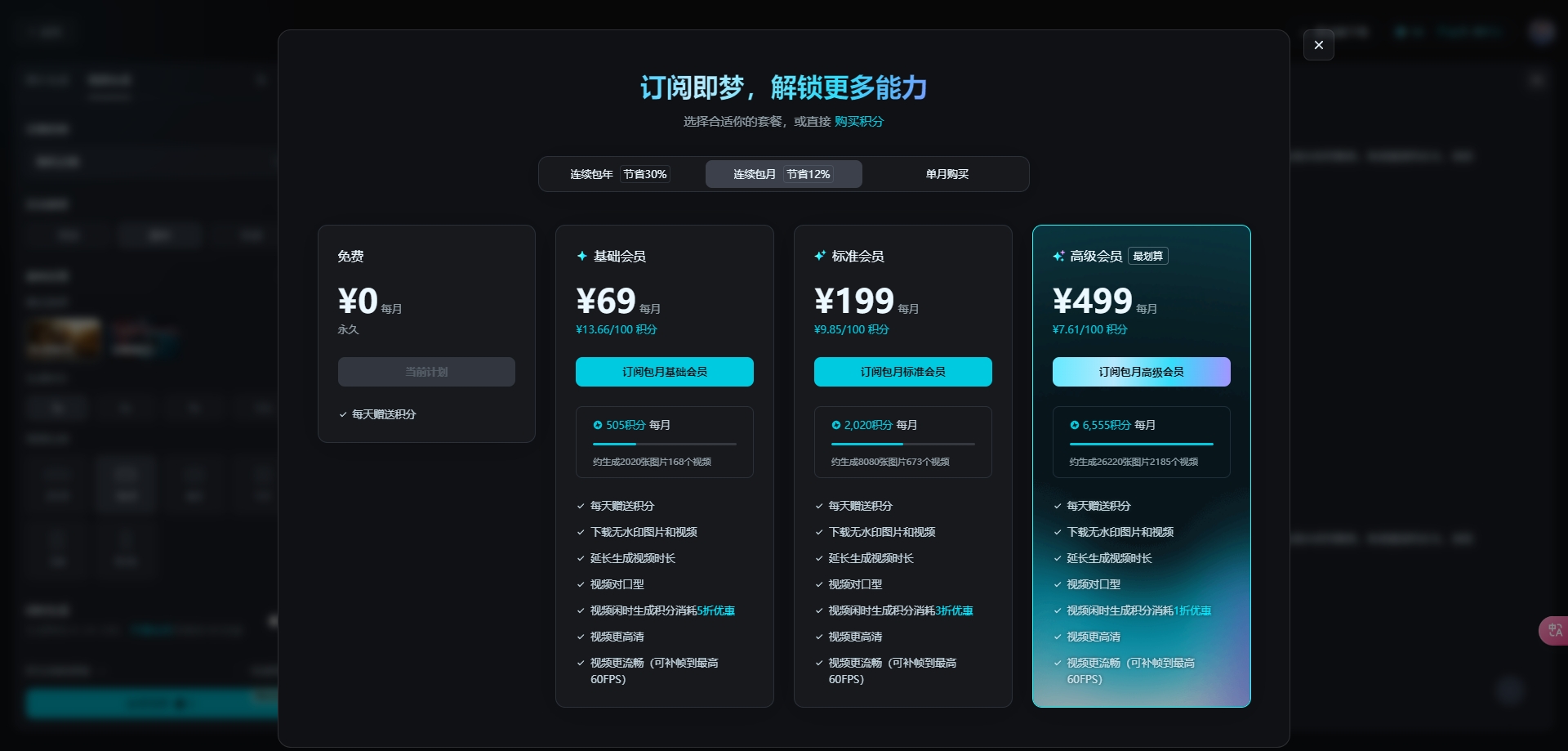
3、Pixverse(最早的国内视频生成应用)
Pixverse刚出来的时候非常低调,全英文的界面不看介绍你很难知道它是国产大模型,定位对标的是Runway。

而它7月24日也发布了最新的V2模型,不过写实性一般,即使是V2模型也还是处于和PIKA一个梯队的。在生成某些卡通风格的还可以。
生成时长:
可以选择5秒和10秒两个选项

优点:
①支持一键生成1-5段连续的视频,单个视频片段最长8秒,多个视频片段最长40秒。而且支持视频的二次编辑。
②Magic Brush 运动笔刷功能,它能精确控制视频元素,就像修图一样修视频。功能对标 Runway 的 Motion Brush,实际效果也不错。
缺点:
①整体水平还是属于PIKA的档位。
使用成本:
初始100积分,每天赠送50积分,生成一个5秒的花15积分,10秒的30积分。

4、智谱清影(赛道新秀)
智谱清言公司出品的视频大模型,属于赛道新秀,目前免费。
在智谱清言官网,点击清影智能体就能开始使用了。

生成时长:
6秒视频,暂不支持延长。
优点:
①可能因为团队有大语言模型的基础,智谱清影在提示词理解方面比较出色。
②相对出的质量比较稳定,个人认为是可以和可灵相媲美的。
③免费!免费!免费!重要的事情说3遍。
缺点:
①选项比较单一,只有视频风格、情感氛围和运镜方式三种可调选项。相比起其他平台可操纵性较小。
②清晰度不行。
③暂不支持延长视频。
使用成本:
暂无使用成本,付费点主要在于付费购买加速包加快排队。

好了,那在讲完了上面之后,大家发现没有,几乎所有的平台都是需要付费的。
要么是付费才能体验最新模型,要么是付费购买会员增加生成次数和加快排队。
总归来讲,都是可以换算成生成每条视频多少刀来算的。
那如果说,不想老是这样靠着每天赠送的积分去生成有限的几条视频,
而是想要多在电脑本地上,无限免费体验的话怎么办呢?
这里就要说到AI视频大模型领域的唯一真神:Stable video diffusion了!
与前面提到的Stable video不同,Stable video是他们团队自己搭建好环境的网页端应用。
实际使用下来的话还是有限制的,生成的内容也是会先经过审核,虽然好处是极大的降低了门槛让人人都能使用,但是缺点也是因为门槛降低了所以限制增加了。

而不想有那么多的限制,就想搭建在自己电脑里面运行,就好像文生图的Stable diffusion那样搞成本地的大模型应用,怎么办呢?
那就下载他们的Stable video diffusion!
使用方式分为两种:在线云部署,电脑本地安装。
1、在线云部署
在线云部署方案适合电脑配置不高,能联网就行的情况,不过本质上这种方式还是经过云端,所以还是会有审核的要求,而且要支付云端部署使用的费用。
典型比如在仙宫云,就有Stable video diffusion的云端应用,选择如下图的SVG方案:

一套应用下来的话,选择4090显卡都是2.57元一个小时,跟去网吧上网一个价格。
生成一个视频也基本在2分钟左右,这么一算下来的话其实还是挺划算的。

2、电脑本地安装
电脑本地安装的话,最低电脑要求是8G显存的GTX1080,安装要求需要Python3.10版本,加上安装Git,会比较吃电脑配置。
如果不符合这个显卡要求,是A卡或显卡版本更老旧一些的情况,那么也不建议走电脑本地安装,直接去云端部署会更方便一些。
具体安装方式的话,在网上搜索Stable video diffusion安装就可以查看相关的视频教程,比看文章全面的多。

总得来讲,现在的AI视频发展,
如果想追求最极致的画面表现力,那么就去使用Runway的Gen3模型。
如果想生成偏短视频风格的趣味画面,那么就去使用可灵。
如果不想每天都靠着积分生成视频,想在电脑本地去体验、学习AI视频创作的话,那么就去下载使用Stable video diffusion。
至于其他的平台,可以按需使用。
讲到这里,如果有关注过AI视频的小伙伴,应该发现这里面是不是缺失了一个关键的名字?
为什么没说到Sora?现在不是全网都在吹Sora吗?为什么这里面没有提到它?

因为Sora直到现在,还没放出公测,目前全网对Sora的分析都是基于Sora官网推出的视频和提示词,来分析它的性能的。
没有经过市场实证的东西,那只能叫做PPT,不能拿来做对比的对象。
只单说为什么Sora被那么万众期待?因为光从演示出来的视频质感和时长就已经领先了。
别家还只能做5秒左右的时候,SORA已经能1分钟了。
而且写实性、稳定性尤其出色,以Sora官网演示的这个视频举例:

视频里同时有多个物体移动时,非常考验画面的稳定性,目前所有的平台都做不到像Sora视频里这么多的数量,还能保证画面的稳定性。
如果Sora真的如他们官网的演示视频所示一样,那么Sora毫无疑问的是AI视频领域的最强王者。
但是在它还没放出公测消息前,就先不讨论它了。
四、现在搞AI视频的人都在怎么赚钱?
那直到上面,我们已经把AI生成视频的基础概念,上限与限制,主流应用平台全部都介绍了一遍。
现在我们来谈谈大家对于AI视频另一个最为关注的地方,现在搞AI视频的人都在怎么赚钱?

坦率地讲,现在确实商业化的前景不太行,如大家所见的,大多都是搞自媒体和搞培训来赚钱,
培训的也是教你烂大街的AI做电影解说,AI做绘本故事这种工作流,
这种实打实的确实没什么人能成功,只有教你赚钱的人在成功。
但若是借着这个信息差,用AI做视频处理方面的服务却还是比较不错的。
比如处理一些工具性的视频应用是还不错,
比如帮别人做场景合成,老照片修复,做AI视频翻译,帮别人做AI去水印,帮别人把照片动起来,帮别人生成风格转绘版的TA,帮别人去除马赛克等。
工具性的应用,AI视频目前发展还是比较不错,
但是对于创意生成领域里面来说,确实是还处在一个发展的前期阶段,除了做自媒体吸粉和做培训外,暂时没有特别落地的商业化应用场景,所以也暂时别想着靠它来赚钱。
就算有些高手凭借AI视频接了视频制作的商单,但也不是纯粹的靠AI就能完成的,基本上都是会搭配很复杂的工作流。
对于小白来说,基本没可能靠着现阶段的AI视频来做商业化的视频,抄词条出张好看的图不难,按想法应用到项目难。
所以,现阶段,AI视频的变现机会,走工具性AI编辑视频的话,相对比较落地。
走创意生成路线的话,那么就还需要比较扎实的扎根在这个领域里面才行。
五、AI视频正在攻破的几个有前景的新方向
好了,说完以上信息后,我们来看看,现阶段AI视频未来可能发展比较有前景的趋势吧。
1、以不同领域细分的AI视频落地应用进行开展
如黄仁勋的omniverse,一句话生成3D场景建模,这一块目前Rodin是做的最好的。

除了场景建模这块,还有诸如3D模型建模的Tropo AI之类的应用可以期待一下之后的发展。
2、多平台工作流整合使用
如最近这几天热火的用FLUX生图,然后用Runway Gen3、可灵AI、Luma Dream Machine等AI视频工具转成视频。
Flux是Stable diffusion原班人马做出的最新的开源可本地安装的生图模型,
最大的特点是现在用Flux生成出来的图片,用它做出来的人物图片,与现实真的没有肉眼可见的差异了。

在画面真实感、对画面里文字的识别度、以及提示词精准控制方面,可以说是划时代的进步。
用Flux出图,然后用RunwayGen3去跑Flux真实感图片,效果最佳。

(备注:该视频为AI生成视频)
这样比起单一的只依靠一个视频平台生成视频来说,从可控性、稳定性、画面效果上来说要好得多,
有部分高手已经能够做出以假乱真的人物产品广告了。
这也是我前面提到的搭配复杂的工作流进行AI商单的变现案例。
六、总结
那到本期内容的最后,我们再来总结一下,今天这期长内容的信息吧。
现阶段,AI视频生成方式分3种:
文生视频(强调创意)、图生视频(更多操作性)、视频转视频(落地性更好)。
目前AI视频主流的生成时长基本都在4-10秒之间,而且不能出现复杂的运动场景,不然画面会整个崩坏。

现阶段,更多是属于创意的辅助工具,距离网上宣传的人人都是导演,以后没有视频工作者的空间了那种程度,还有不少的路子要走。
而目前AI生成视频领域,画面写实感最好的是Runway公司的Gen3模型

我们国产之光可灵则是在短视频、吃播领域表现亮眼。

如果不想花钱买会员生成视频的话,那么使用基于本地部署的Stable video diffusion则是很便利的免费使用AI创作视频的解决方案。

变现机会的话,现阶段确实对于AI视频的话没有非常落地的商业化场景,网上更多的是卖培训的,以及做自媒体吸粉的。
从变现角度上来讲的话,虽然AI视频肯定未来上限很高,但是现如今还只有一些比较小的AI视频处理这种工具性应用的机会。
对AI视频于普通人而言,认识到它目前的局限性,更多是用它来方便某一小部分的日常工作和生活,比如AI去水印,比如用AI做某一个脚本需要的分镜头,比如想不出的画面用它来参考一下展现的灵感。
这些都是能够比较好的帮助我们改进日常工作流的应用。
而从未来发展性来讲,相比起已经初步展现商业化场景落地的AI绘画来说,AI视频才是现在真正的未来可期。
因为AI视频这项技术背后的原理,对于现实物理世界的真实模拟才是可展望前景更大的。说不定它就是我们真正踏入未来元宇宙的关键钥匙。

那以上部分,我们就已经把今天要讲的主题全部说完了,制作本期内容实属不易,
如果对你有帮助的话,请动动你们的大拇指帮本期内容点个赞,你的支持就是我更新创作的最大动力。
那我是浩祥,这里是新个体时代频道,带你探索那些不上班也能挣钱的方式,那我们下期再见!
